 |
 |
| View previous topic :: View next topic |
| Author |
Message |
viki2000
Joined: 08 May 2013
Posts: 233


|
|
 Posted: Tue Jun 13, 2017 8:18 am Posted: Tue Jun 13, 2017 8:18 am |
 |
|
Additional info about CORDIC and implementation in C:
https://en.wikiversity.org/wiki/CORDIC_Hardware_Implementations
https://en.wikibooks.org/wiki/Digital_Circuits/CORDIC
http://www.eetimes.com/document.asp?doc_id=1271838
https://people.sc.fsu.edu/~jburkardt/cpp_src/cordic/cordic.html
http://forums.parallax.com/discussion/88799
I added some text description at the defined numbers in the suggested Cordic code:
| Code: | #include <24HJ64GP202.h>
#use delay(internal=80MHz)
#FUSES FRC_PLL
#FUSES NOWDT //No Watch Dog Timer
#FUSES NOWRTB //Boot block not write protected
#FUSES NOBSS //No boot segment
#FUSES NORBS //No Boot RAM defined
#FUSES NOWRTSS //Secure segment not write protected
#FUSES NOSSS //No secure segment
#FUSES NORSS //No secure segment RAM
#FUSES NOWRT //Program memory not write protected
#FUSES NOPROTECT //Code not protected from reading
#FUSES IESO //Internal External Switch Over mode enabled
#FUSES NOOSCIO //OSC2 is clock output
#FUSES IOL1WAY //Allows only one reconfiguration of peripheral pins
#FUSES CKSFSM //Clock Switching is enabled, fail Safe clock monitor is enabled
#FUSES WINDIS //Watch Dog Timer in non-Window mode
#FUSES PUT128 //Power On Reset Timer value 128ms
#FUSES NOALTI2C1 //I2C1 mapped to SDA1/SCL1 pins
#FUSES NOJTAG //JTAG disabled
#pin_select U1TX=PIN_B6
#pin_select U1RX=PIN_B7
#use rs232(UART1, BAUD=115200, ERRORS)
// CORDIC based SIN and COS in 16 bit signed fixed point math
// Based on http://www.dcs.gla.ac.uk/~jhw/cordic/
// Function is valid for arguments in range -pi/2 -- pi/2
// For values pi/2--pi: value = half_pi-(theta-half_pi) and similarly for values -pi---pi/2
//
// 1.0 = 16384
// 1/k = 0.6072529350088812561694
// pi = 3.1415926536897932384626
// Some useful Constants
#define M_PI 3.1415926535897932384626
#define cordic_1K 0x26DD //=9949=16384*0.60726, 0.60726 is "cordic gain"
// cordic gain: COS(45)*COS(26.565)*COS(14.036)*COS(7.125)*COS(3.576)*COS(1.790)*COS(0.895)*COS(0.448) = 0.60726
#define half_pi 0x6487 //=25735=16384*(M_PI/2), PI/2 is 90°...25735=0x6487
#define MUL 16384.0
#define CORDIC_NTAB 16 //Maximum Cordic iterations
int s, c;
// 45°...12867=0x3243, 26.565°...7596=0x1DAC, 14.036°, 7.125°, 3.576°, 1.790°,
// 0.895°, 0.448°, 0.224°, 0.112°, 0.056°, 0.028°, 0.014°, 0.007°, 0.003°
// tan(45°)=1, tan(26.565°)=0.5, tan(14.036°)=0.25, tan(7.125°)=0.125...
int cordic_ctab [16] = {0x00003243, 0x00001DAC, 0x00000FAD, 0x000007F5, 0x000003FE,
0x000001FF, 0x000000FF, 0x0000007F, 0x0000003F, 0x0000001F, 0x0000000F, 0x00000007,
0x00000003, 0x00000001, 0x00000000, 0x00000000};
void cordic(int theta, int *s, int *c, int n);
void main(){
float p, p1;
int i;
while(TRUE)
{
for(i=0; i<1000; i=i+1){
p = (i/1000.0)*M_PI/2;
p1=p*MUL;
cordic(p1, &s, &c, 14); // 14 Cordic iterations
//Send to serial port
putc(make8(s,1)); //MSB
putc(make8(s,0)); //LSB
//delay_ms(100);
}
}
}
void cordic(int theta, int *s, int *c, int n){
int k, d, tx, ty, tz;
int x=cordic_1K,y=0,z=theta;
n = (n>CORDIC_NTAB) ? CORDIC_NTAB : n;
for (k=0; k<n; ++k)
{
//d = z>>15;
//get sign. for other architectures, you might want to use the more portable version
d = z>=0 ? 0 : -1;
tx = x - (((y>>k) ^ d) - d);
ty = y + (((x>>k) ^ d) - d);
tz = z - ((cordic_ctab[k] ^ d) - d);
x = tx; y = ty; z = tz;
}
*c = x; *s = y;
} |
The code did not work properly due to the sign, variable d in cordic subroutine.
I changed “d = z>>15;” with recommended “d = z>=0 ? 0 : -1;”.
I have tried 10 and 16 and 14 iterations.
Now I get the sine points, but with important errors of approximation at the end, towards 90°. Besides that there is a glitch somewhere at small angle 3.4°-4.4°.
Here is the Excel chart: https://goo.gl/wnrIez
It needs further debugging and I have no idea for the moment from where these errors come and what can be done to remove them and improve the accuracy. |
|
 |
RF_Developer
Joined: 07 Feb 2011
Posts: 839
|
|
| Posted: Tue Jun 13, 2017 10:31 am |
|
|
What is the "best" way to calculate sin(x) (or cos(x) or whatever)?
That simple question has many different answers, and as we've tried to explain over and over, what is "best" depends on your application. Best, perhaps surprisingly but it really shouldn't be, doesn't often mean "fastest", nor necessarily "most accurate". Also, you must bear in mind that best speed and accuracy/precision can rarely, if ever be had at the same time and that any choice trades off one against the other.
It is impossible to precisely compute sin(x). You will never get a totally precise value of sin(x). That is because it is an infinite series which can not be computed: it would take infinite time. So, all computations, not some or most, but ALL computations of sin(x) are approximations. The "best" from a mathematician's perspective would be the full sine series, which can be precisely expressed as an infinite integral, but which cannot be precisely computed.
So what can you compute? Well, you can compute an approximation to sin(x) to any specified finite precision. Computers do it all the time. The questions, as with all practical computations is how precise, how long will it take, and what resources are needed?
One thing to get past is that all computations, all approximations can be no better than +/-one half least significant bit. In floating point that's of the mantissa, but for fixed point its of all the available bits. Hold that thought...
Apparently, Excel uses a early variant of IEEE754 binary64 (i.e. 64 bit floating point, or double precision float). I can pretty much guarantee that it uses the floating point co-processor hardware integrated in the the CPU cores, and that will use a Tchebychev-based polynomial approximation. Excel is no more "right" than any other computation done to the same. As I said before there are reasons why Tchebychev is used, and that it a) give known errors, which are chosen to as close to the available precision of the floating point format as is practical and b) it is known and proved to converge fastest, i.e. to use the least terms to give the required precision. Done right, it is a accurate and fast as any approximation using floating point format can be. That's not to say its guaranteed to be done right, Intel have been known to make significant floating point implementation errors...
The CCS routines essentially do the same, but implemented using firmware rather than floating point hardware. On PIC24s as I described before there are 32 (float), 48 and 64 (double) bit floating point implementations of sin() and cos(). You can hope, though probably not expect that the 64 bit, double, version gives essentially the same result as Excel. The problem is that the floating point hardware in the PC, and hence Excel, probably uses a longer mantissa internally, if only by a few bits probably, with greater potential precision (but still no better that +/-half a bit, though its likely to hit that more often), than the C version which can only have the 24 bit internal precision allowed by the double format.
For most of us, most of the time the CCS sin() is the "best". Why? Because its there, is known to work, is easy to use and we don't need anything faster or more precise. Therefore its a no brainer: use it. It saves a lot of development time, and in general, in real projects, that's where most of the cost goes: development. Anything that saves time and money and gets our product to market sooner is a plus. Therefore we'll use the CCS routines more than 99% of the time. They are the "best".
Well, of course they aren't the absolute best in all circumstances. Sometimes, rarely, we might want something faster, in which case a different approximation might be more appropriate, or a pure integer implementation, but they are likely not to give the same accuracy or precision. Even 23 bit float has a 24 bit mantissa, and if done right will always produce a more precise result than a 16 or 15 bit implementation.
CORDIC offers another route, but your have to remember where it came from and why it was developed. it was an analogue computing thing. Analogue computers, while remarkably powerful in their own way, were great at adding and multiplying by constants (op-amps do that no trouble at all) and were pretty good at integrating and differentiating (hence were great for PID control, which was first developed for analogue computing), but they were poor at multiplying changing values (mult by constant was easy, just set up an amplifier with the right gain ad your there). The CORDIC process was developed as a way of doing trig functions with such analogue computers, which were bad and multiplying. Hence CORDIC essentially uses just additions, with a few constant multiplications thrown in for scaling. It is an iterative process, which is easy enough to implement in analogue by using feedback.
CORDIC is especially useful in some digital applications, where hardware multiplication is not available... but it is on most PICs, and 24s have a full 16x16 hardware single cycle hardware multiplier, so multiplications are just as fast as additions, hence CORDIC's unique selling point is nullified. It's iterative approach will always be slower than a well implemented polynomial method, which goes in one pass. CORDIC's time has largely passed.
Polynomials can also be computed fairly simply with a bit of reorganisation. Writing them as f*x^5 + e*x^4 + d*x^3... and so on hides the computational short cuts that can be used. You start off with the x, multiplying by its constant, then you multiply x by x and the x^2 constant, then multiply by x again, and the x^3 constant and so on. Some DSPs have hardware to do this, and can evaluate polynomials very fast indeed. I'm not sure if the dsPIC have it, but its the sort of thing they might have. Leveraging such hardware can make polynomial evaluation almost as easy and fast as addition. There are almost certainly DDS chips that use such hardware internally to generate its output, in fact, I can see almost no reason to use anything else.
I could go on and on, but I have to go home now. Please, please think again about what you are trying to do. Currently you are bogged down in what is essentially a blind alley. Which tends to be what happens if you don't have any particular direction to go in. There is no best way of computing sin(x). There are many best ways depending on what your requirements and resources are. They are all trade offs. They are approximations, of varying precision. |
|
|
viki2000
Joined: 08 May 2013
Posts: 233
|
|
| Posted: Tue Jun 13, 2017 11:39 am |
|
|
Good thoughts to approach the problems in principle.
Let’s go particular.
I want to use as reference for accuracy and speed of execution the _Q15sinPI (libq.h, actually is libq-elf.a) from XC16 Microchip.
The idea of using fixed point math, the 16 bit integers instead of float sin function is the speed, even if we lose accuracy when we produce sine signal. That is the reason why I do not want to use sin() from math.h inside CCS.
The max. deviation between sine calculated with sin() Excel function and sine from _Q15sinPI function inside the PIC is 0.00759%, which I find very good and I do not know what algorithm was implemented to get that.
The polynomial approach proposed by Ttelmah gave me 0.111% max. deviation compared with the sine calculated with sin() Excel function.
About Cordic I did not hear and I was curious to try it and see what precision offers based on different number of iterations.
Maybe are also other polynomial approaches, of higher order with a better precision, as described here for example: http://www.coranac.com/2009/07/sines/ , but maybe I will try that later.
What I am trying to do is to find out and learn, what would be the best approach, approximation, subroutine, which can offer similar accuracy and speed as _Q15sinPI from XC16 Microchip.
If I use as reference _Q15sinPI from XC16 Microchip, then why I do not stick with XC16 to the end?
Because CCS offers better, nicer subroutines for other functions, especially easy communications setup. |
|
|
temtronic
Joined: 01 Jul 2010
Posts: 9097
Location: Greensville,Ontario
|
|
| Posted: Tue Jun 13, 2017 12:19 pm |
|
|
re:
What I am trying to do is to find out and learn, what would be the best approach, approximation, subroutine, which can offer similar accuracy and speed as _Q15sinPI from XC16 Microchip.
If you're dead stuck on using _Q15sinPI as your 'best' implementation then simply convert that code into the equal using CCS C.
All that's required is the listing of the 'best', then cut code, compile, compare the CCS C listing to the uChip XC16 listing.
This is not hard to do, maybe an hour or two, depending on how well you type..
Jay |
|
|
viki2000
Joined: 08 May 2013
Posts: 233
|
|
| Posted: Tue Jun 13, 2017 1:41 pm |
|
|
_Q15sinPI is encoded in a library "libq-elf.a" which I cannot see/open. Then remains only to compile the project XC16 and look into .lst, assembly code, but I hoped for a C subroutine.
Coming back to the proposed cordic, I am puzzled by the fact that these guys used the same cordic code and have positive result:
http://www.stm32duino.com/viewtopic.php?t=1510
I noticed the constant half_pi is defined "#define half_pi 0x00006487" but not used.
I started the debugging of the proposed cordic subroutine in an unconventional way.
I "exploded" the subroutine expanding the iteration in Excel cells. There are errors on calculating variable "tz" due to the same "d" sign variable. I will try to dig more, but any suggestion is appreciated.
Here is the Excel with the "exploded" cordic subroutine:
https://goo.gl/mxYWQz |
|
|
temtronic
Joined: 01 Jul 2010
Posts: 9097
Location: Greensville,Ontario
|
|
| Posted: Tue Jun 13, 2017 2:46 pm |
|
|
Actually assembly is not that hard to learn. Heck, less instructions than PICs have 'fuses' these days !!
To get the 'best' perforamnce, you should use assembly anyway. When you become a 'low level' programmer you have more control over how the code is generated. Depending on who wrote the compiler, it might be optimised for speed, memory use or ??? !
Jay |
|
|
Ttelmah
Joined: 11 Mar 2010
Posts: 19215
|
|
| Posted: Wed Jun 14, 2017 12:34 am |
|
|
Remember this is an int16 representation of a number with decimals. An integer 16384* the value.
So 0.5 PI = 1.5707963
1.5707963 * 16384 = 25735.927
25735 in hex is 0x6487
However in fact if they were using this 0x6488, would really be the more accurate conversion.
The reason they have this defined, is that this is the range limit for the function. Remember just one bit in front of the decimal, so the function is rated to work between +Pi/2 and -PI/2. |
|
|
viki2000
Joined: 08 May 2013
Posts: 233
|
|
| Posted: Wed Jun 14, 2017 1:33 am |
|
|
I will come to these numbers later, but first the idea of looking at the listing file, the assembly of the XC16 project that uses Q15sinPI.
MPLABX with XC16 provides listing.disasm view/file after compilation with next content:
https://goo.gl/9n9zMu
So, I see nothing except “RCALL __Q15sinPI”
Usually the intermediary files are deleted, but if I set MPLABX + XC16 to generate .lst file as suggested here: https://www.eevblog.com/forum/microcontrollers/mplabx-xc16-generate-assembly-listing-file-coff-elf-agnostic/
then I get next:
https://goo.gl/voce0R
Here I can see the Q15sinPI in assembly. The above recall is “rcall 0x2cc <__Q15sinPI>” and the function is this:
| Code: | 000002cc <__Q15sinPI>:
2cc: 00 01 78 mov.w w0, w2
2ce: 01 00 28 mov.w #0x8000, w1
2d0: 00 00 eb clr.w w0
2d2: 01 10 e7 cpsne.w w2, w1
2d4: 00 00 06 return
2d6: 88 1f 78 mov.w w8, [w15++]
2d8: 18 00 20 mov.w #0x1, w8
2da: 00 10 e6 cpsgt.w w2, w0
2dc: f8 ff 2f mov.w #0xffff, w8
2de: 08 90 b9 mul.ss w2, w8, w0
2e0: 12 00 24 mov.w #0x4001, w2
2e2: 03 00 28 mov.w #0x8000, w3
2e4: 02 80 e6 cpslt.w w0, w2
2e6: 00 80 51 sub.w w3, w0, w0
2e8: f2 8b 22 mov.w #0x28bf, w2
2ea: 02 00 e1 cp.w w0, w2
2ec: 28 00 3d bra GE, 0x33e <SinePI_CosCall>
2ee: 82 48 26 mov.w #0x6488, w2
2f0: 02 81 b9 mul.ss w0, w2, w2
2f2: 04 00 21 mov.w #0x1000, w4
2f4: 04 01 41 add.w w2, w4, w2
2f6: e0 81 49 addc.w w3, #0x0, w3
2f8: 4d 11 de lsr.w w2, #0xd, w2
2fa: 43 1a dd sl.w w3, #0x3, w4
2fc: 04 00 71 ior.w w2, w4, w0
2fe: 00 01 78 mov.w w0, w2
300: 50 bb 26 mov.w #0x6bb5, w0
302: f1 ff 27 mov.w #0x7fff, w1
304: 01 10 e7 cpsne.w w2, w1
306: 1a 00 37 bra 0x33c <L_SIN_PI_RETURN>
308: b0 44 29 mov.w #0x944b, w0
30a: 11 00 28 mov.w #0x8001, w1
30c: 01 10 e6 cpsgt.w w2, w1
30e: 16 00 37 bra 0x33c <L_SIN_PI_RETURN>
310: 02 93 b9 mul.ss w2, w2, w6
312: 4f 33 de lsr.w w6, #0xf, w6
314: c1 3b dd sl.w w7, #0x1, w7
316: 87 01 73 ior.w w6, w7, w3
318: c1 19 dd sl.w w3, #0x1, w3
31a: 03 12 b9 mul.su w2, w3, w4
31c: 51 55 25 mov.w #0x5555, w1
31e: 01 ab b9 mul.ss w5, w1, w6
320: c1 bb de asr.w w7, #0x1, w7
322: 07 00 51 sub.w w2, w7, w0
324: 03 2a b9 mul.su w5, w3, w4
326: 41 44 24 mov.w #0x4444, w1
328: 01 ab b9 mul.ss w5, w1, w6
32a: c5 bb de asr.w w7, #0x5, w7
32c: 07 00 40 add.w w0, w7, w0
32e: 03 2a b9 mul.su w5, w3, w4
330: 71 80 26 mov.w #0x6807, w1
332: 01 ab b9 mul.ss w5, w1, w6
334: 05 40 20 mov.w #0x400, w5
336: 85 83 43 add.w w7, w5, w7
338: cb bb de asr.w w7, #0xb, w7
33a: 07 00 50 sub.w w0, w7, w0
0000033c <L_SIN_PI_RETURN>:
33c: 31 00 37 bra 0x3a0 <SIN_PI_END>
0000033e <SinePI_CosCall>:
33e: 03 00 24 mov.w #0x4000, w3
340: 00 80 51 sub.w w3, w0, w0
342: 82 48 26 mov.w #0x6488, w2
344: 02 81 b9 mul.ss w0, w2, w2
346: 04 00 21 mov.w #0x1000, w4
348: 04 01 41 add.w w2, w4, w2
34a: e0 81 49 addc.w w3, #0x0, w3
34c: 4d 11 de lsr.w w2, #0xd, w2
34e: 43 1a dd sl.w w3, #0x3, w4
350: 04 00 71 ior.w w2, w4, w0
352: 11 f0 2f mov.w #0xff01, w1
354: f2 0f 20 mov.w #0xff, w2
356: 01 00 e1 cp.w w0, w1
358: 23 00 35 bra LT, 0x3a0 <SIN_PI_END>
35a: 02 00 e1 cp.w w0, w2
35c: 02 00 3c bra GT, 0x362 <L_SIN_PI_Cos_Else>
35e: f0 ff 27 mov.w #0x7fff, w0
360: 1f 00 37 bra 0x3a0 <SIN_PI_END>
00000362 <L_SIN_PI_Cos_Else>:
362: 00 01 78 mov.w w0, w2
364: 01 00 28 mov.w #0x8000, w1
366: 90 52 24 mov.w #0x4529, w0
368: 01 10 e7 cpsne.w w2, w1
36a: 1a 00 37 bra 0x3a0 <SIN_PI_END>
36c: f1 ff 27 mov.w #0x7fff, w1
36e: f0 ff 27 mov.w #0x7fff, w0
370: 02 92 b9 mul.ss w2, w2, w4
372: 4f 22 de lsr.w w4, #0xf, w4
374: c1 2a dd sl.w w5, #0x1, w5
376: 05 02 72 ior.w w4, w5, w4
378: 41 22 dd sl.w w4, #0x1, w4
37a: 01 a1 b8 mul.us w4, w1, w2
37c: 07 00 28 mov.w #0x8000, w7
37e: 07 1b b9 mul.su w3, w7, w6
380: 07 00 50 sub.w w0, w7, w0
382: 03 a1 b8 mul.us w4, w3, w2
384: 57 55 25 mov.w #0x5555, w7
386: 07 1b b9 mul.su w3, w7, w6
388: c3 bb de asr.w w7, #0x3, w7
38a: 07 00 40 add.w w0, w7, w0
38c: 03 a1 b8 mul.us w4, w3, w2
38e: 37 d8 22 mov.w #0x2d83, w7
390: 07 1b b9 mul.su w3, w7, w6
392: c7 bb de asr.w w7, #0x7, w7
394: 07 00 50 sub.w w0, w7, w0
396: 03 a1 b8 mul.us w4, w3, w2
398: 07 0d 20 mov.w #0xd0, w7
39a: 07 1b b9 mul.su w3, w7, w6
39c: c7 bb de asr.w w7, #0x7, w7
39e: 07 00 40 add.w w0, w7, w0
000003a0 <SIN_PI_END>:
3a0: 08 80 b9 mul.ss w0, w8, w0
3a2: 4f 04 78 mov.w [--w15], w8
3a4: 00 00 06 return |
|
|
|
viki2000
Joined: 08 May 2013
Posts: 233
|
|
| Posted: Wed Jun 14, 2017 4:40 am |
|
|
I found the errors inside the Excel sheet that I tried to use to emulate the cordic subroutine. Some of them were related with cell references and some with my confusion about “^” symbol, which in C is bitwise xor and in Excel is x to power of y. Besides that I used Excel 2013, which has Bitwise XOR and also Excel 2010, which does not have that function, so I had to implement it in VBA. Now I work with Excel 2010 enabled macro workbook and the values are fine in the emulation sheet.
The y column gives the sine value and x gives the cosine values after k=10 iterations.
I used 50 steps for the angle between 0..PI/2 and I calculated for the first 5 angles and the last 5 angles with 10 iterations for each angle.
The file is here: https://goo.gl/7HjqF1
Then I compared with the PIC computations and I saw differences, errors from PIC side.
I need your help to understand what I neglect inside the PIC, why do I get the following simple computational error.
I have a programmer that I can use also as debugger: ICD-U64 from CCS.
I compiled the program and in the Watches list I look at the variables inside cordic subroutine.
I start with angle 0 and everything matches the Excel calculation up to the 4th iteration (k=3), but when I reach the 5th iteration (k=4) inside the cordic subroutine, then I get a calculation error for tx variable.
Excel tells me that I should get 16372.
The Watches list tells me that tx is 12274.
It supposed to be the same number or very close.
Then I go to evaluation Eval tab and I write “tx” without commas and I get 12274 and then I write the expression of tx, which is “x-(((y>>k)^d)-d)” and I get 16370, which is acceptable, close to Excel.
Why “tx” and its equivalent expression “x-(((y>>k)^d)-d)” give different results? How is that possible? It should be the same number. What is happening? What is wrong with the PIC? Or do I neglect something that I suppose to know?
It is a big computational difference between 16370 and the wrong value 12274. And that I see in “real time”. The code used is the same as above, except that I used the “dummy” variable to have a breakpoint clear defined between computations.
How do we approach such kind of problem?
See for yourself:
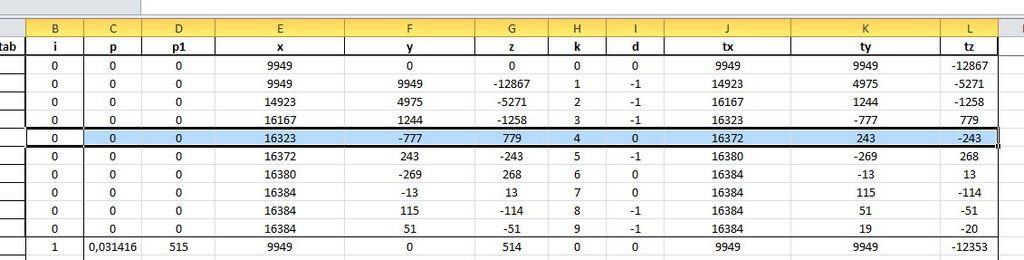
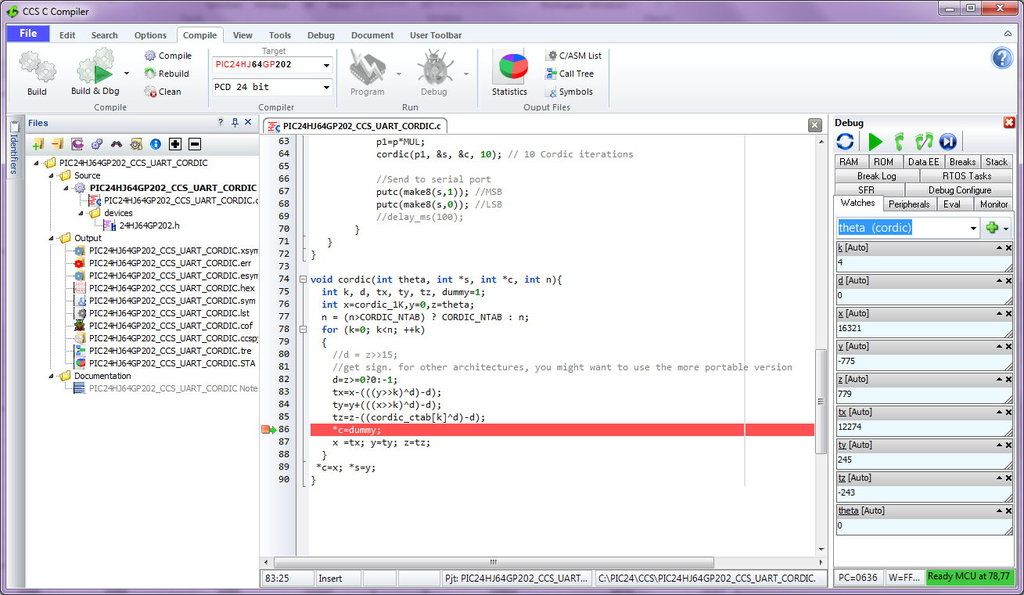
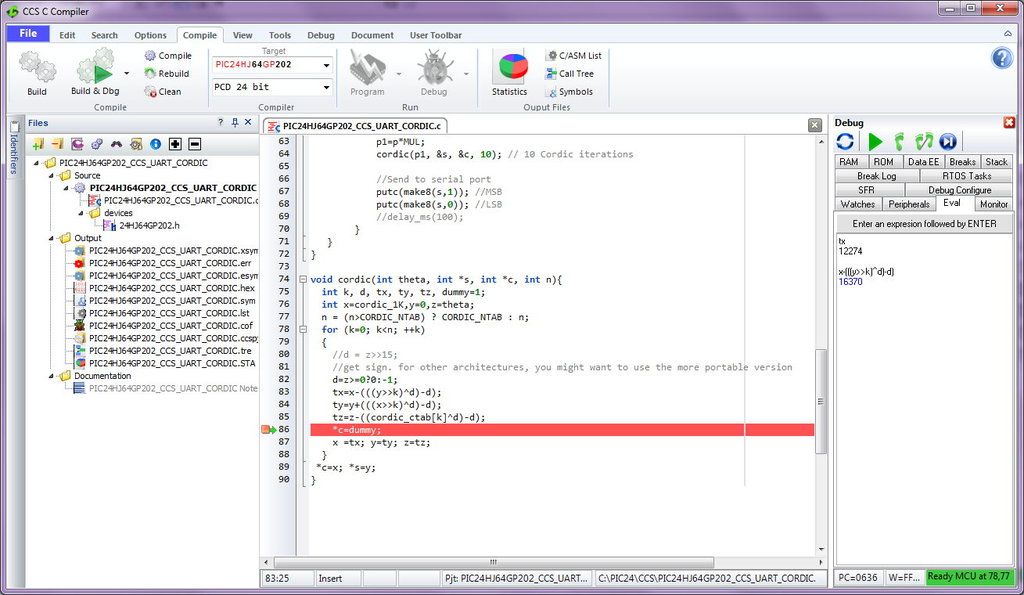 |
|
|
Ttelmah
Joined: 11 Mar 2010
Posts: 19215
|
|
| Posted: Wed Jun 14, 2017 4:49 am |
|
|
OK.
Now you've still not actually explained why you are so worried about accuracy. Problem is that the half wave waveform you are working with is going to give inherently large inaccuracies at the transition point between the half cycles, unless you have hardware that can handle very high frequencies indeed. The half wave involves having all the even harmonics, with some terms at frequencies way above the fundamental, still having large components. As such the inherent errors from trying to synthesise this are going to be much larger than the errors from the maths....
Which is again back to 'much easier to synthesise a pure sin, and rectify it'.
Now the point about the polynomial synthesis, is that it is quick, and gives results that are 'well behaved', so giving smooth terms and covering the whole sinusoid. The integer cordic form, can be made to give quite good accuracies, but only by going to high numbers of terms, which then slows it down. So we are back to 'why not just just use a lookup'...
You said you didn't want to fiddle with having to 'extend' the lookup so using one table to give all four quadrants, but this has to be done for the cordic synthesis as well (in fact has to be done for all sinusoidal synthesis algorithms...).
The problem you are having with cordic, is because of the 'implementation specific' nature of the >> operator. If you read the C textbooks you will see that on some languages this remains as a logical shift right, while others implement it as a 'mathematical shift right' (so handling the sign for -ve numbers).
So, The cordic 16 coded round this:
| Code: |
#include <math.h> //Just to get PI
#define cordic_1K 0x000026DD
#define half_pi 0x00006487
#define MUL 16384.000000
#define CORDIC_NTAB 16
// 45°...12867=0x3243, 26.565°...7596=0x1DAC, 14.036°, 7.125°, 3.576°, 1.790°,
// 0.895°, 0.448°, 0.224°, 0.112°, 0.056°, 0.028°, 0.014°, 0.007°, 0.003°
// tan(45°)=1, tan(26.565°)=0.5, tan(14.036°)=0.25, tan(7.125°)=0.125...
signed int16 cordic_ctab [16] = {0x00003243, 0x00001DAC, 0x00000FAD, 0x000007F5, 0x000003FE,
0x000001FF, 0x000000FF, 0x0000007F, 0x0000003F, 0x0000001F, 0x0000000F, 0x00000007,
0x00000003, 0x00000001, 0x00000000, 0x00000000};
#inline
signed int16 math_shift(signed int16 x, signed int16 y)
{ //Perform a mathematical right shift on a signed value
if (bit_test(x,15)) //if -ve
return -(-x>>y); //convert sign, shift, and convert back
return x>>y; //otherwise simple shift
}
void cordic_sin16(signed int16 theta, signed int16 &s, int n)
{ //Using reference parameter so value is returned directly to calling routine
int ctr;
signed int16 x=cordic_1K,y=0,dx,dy;
for (ctr=0;ctr<n;ctr++)
{
if (bit_test(theta,15)) //Quicker to test once
{ //-ve value here
theta=theta+cordic_ctab[ctr];
dx=x+math_shift(y,ctr);
dy=y-math_shift(x,ctr);
}
else
{ //+ve value here
theta=theta-cordic_ctab[ctr];
dx=x-math_shift(y,ctr);
dy=y+math_shift(x,ctr);
}
x=dx;
y=dy;
}
s=y; //place the value back
}
#define STEP ((PI*16384)/2000) //floating point step size
void main(void)
{
float theta;
signed int16 sin;
int test, test2;
while(TRUE)
{
for (test=0; test>-128;test--)
{
//test shifts on -ve numbers
test2 = test>>1;
test2=test>>2;
}
for(theta=0; theta<((PI*16384)/2); theta+=STEP){
cordic_sin16((signed int16)theta, sin, 14); // 14 Cordic iterations
//Send to serial port
//printf ("%04x\n", sin); //for testing
putc(make8(sin,1)); //MSB
putc(make8(sin,0)); //LSB
}
}
}
|
|
|
|
temtronic
Joined: 01 Jul 2010
Posts: 9097
Location: Greensville,Ontario
|
|
| Posted: Wed Jun 14, 2017 7:06 am |
|
|
I get the impression that the OP is a 'numbers' guy who needs to find the 'best' solution when in reality there are been presented several 'very good - will work fine in the Real World' solutions.
Everyone who has been using using for any time(some of us a 1/4 century) KNOW that PICs were never designed for floating point calculations, it just wasn't designed for it. Ideally you'd use another processor or even a FP chip like the PC did and still does.
Makes me wonder if anyone has interfaced an FP chip to a PIC ? Now that would be good for a thesis... 'time/accuracy comparisons of using FP chip with PIC'.
Jay |
|
|
Ttelmah
Joined: 11 Mar 2010
Posts: 19215
|
|
| Posted: Wed Jun 14, 2017 7:13 am |
|
|
There was a project done with an FP processor years ago, but I don't think the processor used is made any more. However one company sells a PIC18, programmed with a maths library for use as a 'subsidiary' maths processor on one particular PIC system. The idea is you offload the maths too this, while your main processor gets on with doing other things. I think Sparkfun still sell this. This though is slow...
The other comment made early on about the serial still applies. As it stands if a bit gets lost, the whole communication could become screwed. If this is what he intends to use in the end, then it needs to be 'rethought'.... |
|
|
viki2000
Joined: 08 May 2013
Posts: 233
|
|
|
Ttelmah
Joined: 11 Mar 2010
Posts: 19215
|
|
| Posted: Wed Jun 14, 2017 9:14 am |
|
|
| It takes twice as long to run though.... |
|
|
viki2000
Joined: 08 May 2013
Posts: 233
|
|
| Posted: Thu Jun 15, 2017 5:40 am |
|
|
I used the simple communication with serial port in a continuous loop to send the data only for test purpose to analyze the data in PC, not for final implementation.
A bit more info about arithmetic shift right, because it gave me that headache.
Microchip gives next explanation about their C compilers:
http://microchipdeveloper.com/tls2101:shift-operators
then another discussion on the subject with a slightly different implementation:
http://www.microchip.com/forums/m98041.aspx
similar with rotate right from here: https://en.wikibooks.org/wiki/C_Programming/Simple_math
One more discussion from 2012 that gave similar trouble between XC8 (HITECH C) and MPLAB C18
http://www.microchip.com/forums/m677639.aspx
“When right shifting a signed integer, HITECH C does sign extension and MPLAB C18 does not. XC8 is based on HITECH C, so it will propagate the sign bit.”
I learned that we have to pay attention always to the C compiler, how shift right is implemented.
If I use your math shift right subroutine, then of course the original code works.
| Code: | #inline
signed int16 math_shift(signed int16 x, signed int16 y)
{ //Perform a mathematical right shift on a signed value
if (bit_test(x,15)) //if -ve
return -(-x>>y); //convert sign, shift, and convert back
return x>>y; //otherwise simple shift
}
void cordic(int theta, int *s, int *c, int n){
int k, d, tx, ty, tz;
int x=cordic_1K,y=0,z=theta;
n = (n>CORDIC_NTAB) ? CORDIC_NTAB : n;
for (k=0; k<n; ++k)
{
//d = z>>15;
//get sign. for other architectures, you might want to use the more portable version
d=z>=0?0:-1;
tx=x-((math_shift(y,k)^d)-d);
ty=y+((math_shift(x,k)^d)-d);
tz=z-((cordic_ctab[k]^d)-d);
x =tx; y=ty; z=tz;
}
*c=x; *s=y;
} |
The test result with 50 points/angles and 10 iteration for one angle is here: https://goo.gl/GR2KyR
And works also with proposed code from here: http://www.microchip.com/forums/m98041.aspx
| Code: | void cordic(int theta, int *s, int *c, int n){
int k, d, tx, ty, tz;
int x=cordic_1K,y=0,z=theta;
n = (n>CORDIC_NTAB) ? CORDIC_NTAB : n;
for (k=0; k<n; ++k)
{
//d = z>>15;
//get sign. for other architectures, you might want to use the more portable version
d=z>=0?0:-1;
tx=x-((((y >> k) | (((int)y < 0)?(0xffff << (16-k)):0))^d)-d);
ty=y+((((x >> k) | (((int)x < 0)?(0xffff << (16-k)):0))^d)-d);
tz=z-((cordic_ctab[k]^d)-d);
x =tx; y=ty; z=tz;
}
*c=x; *s=y;
} |
But I like your math shift right subroutine better, because it is easier to understand it at the first view, having not so many operations in it.
Speaking about the speed of execution, I measured it today by toggling one pin on/off before the sine subroutine/function and after that and looking with the oscilloscope at the signal. The PIC used is PIC24HJ64GP202 at 80MHz internal clock.
The XC16 _Q15sinPI executes the calculation of one sin() angle value in 1.88us.
The CCS Polynomial executes the calculation of one sin() angle value in 30.72us.
The CCS Cordic executes the calculation of one sin() angle value in 21.55us for 14 iterations and in 15.54us for 10 iterations.
The CCS float sin() from math.h executes the calculation of one sin() angle value in 77.45us.
The XC16 float sin() from math.h executes the calculation of one sin() angle value in 6.2us.
It seems that XC16 is always 10 times faster when comes to compute sin(), no matter if it is float from math.h or fixed point math with 16bit signed integers.
CCS needs better implementation for math libraries and would be nice to have also dedicated fixed point math as XC16 has with this _Q15sinPI. |
|
|
|
|
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
|
Powered by phpBB © 2001, 2005 phpBB Group
|

